


In this article, we will continue our exploration of data modeling approaches, delving deeper into the different techniques and strategies that can be employed to maximize the power of data engineering. Understanding these approaches is crucial for data professionals looking to master the art of data modeling. So, let's jump right in and explore the world of data models and their applications.
Note: If you haven’t read the first part please read it here.
Understanding Different Data Modeling Approaches
Data models are fundamental tools used to represent and organize data in a structured manner. They provide a framework for understanding and managing data in various systems and applications. There are three main types of data models: conceptual, logical, and physical. Each model serves a specific purpose in the data modeling process.
Exploring the Conceptual, Logical, and Physical Data Models
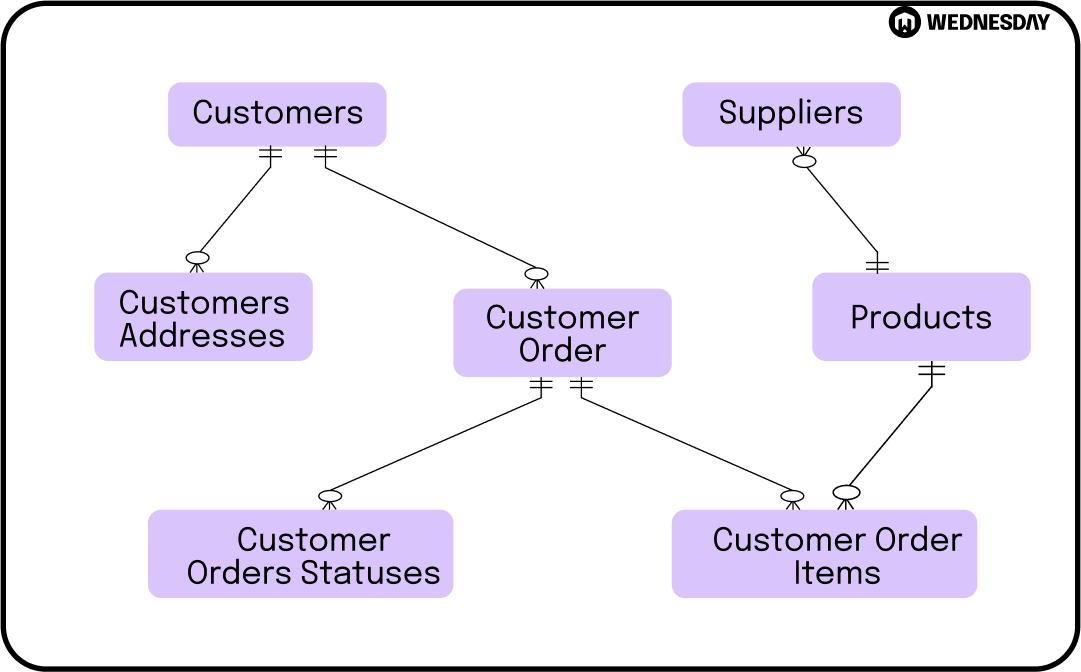
The conceptual data model focuses on defining the high-level business concepts and their relationships. It sets the foundation for the rest of the data modeling process, providing a big-picture view of the data requirements. This model helps stakeholders and data architects understand the overall structure and scope of the data.
The logical data model takes the conceptual model a step further by translating the business concepts into more detailed entities, attributes, and relationships. It aims to capture the essence of the data structure and business rules. This model helps in designing the database schema and provides a blueprint for the implementation phase.
The physical data model represents the actual implementation of the data model in a specific database system. It includes details such as table structures, data types, indexes, and constraints. The physical model is optimized for performance and storage efficiency. It provides the technical specifications required for building and maintaining the database.
Comparing Hierarchical, Network, and Object-Role Data Modeling
Once the data modeling basics are clear, it's time to explore different data modeling techniques and approaches. Three popular approaches are hierarchical, network, and object-role data modeling.
In hierarchical data modeling, data is organized in a tree-like structure, where each parent can have multiple children but each child has only one parent. This approach is useful for representing parent-child relationships where each child entity is directly related to its parent entity. It provides a simple and intuitive way to represent data relationships.
In network data modeling, data is represented as a collection of records, and relationships are established using pointers or links. This allows for more complex relationships, enabling entities to have multiple connections with one another. It is particularly beneficial for modeling many-to-many relationships, where entities can be connected to multiple other entities.
On the other hand, object-role data modeling is a technique that focuses on capturing both the structure and behavior of data. It treats data as objects with defined roles, allowing for more flexibility and adaptability in modeling complex domains. This approach is commonly used in object-oriented programming and database systems.
Each data modeling approach has its strengths and weaknesses, and the choice of the appropriate approach depends on the specific requirements and characteristics of the data being modeled. Understanding these different approaches and their implications is crucial for designing effective and efficient data models.

Mastering Data Modeling Techniques
Unleashing the Power of Dimensional Modeling
One of the most widely used data modeling techniques is dimensional modeling. It is specifically designed for data warehousing and business intelligence applications, providing a flexible and intuitive way to organize and analyze data.
Dimensional modeling revolves around two main components: dimensions and facts. Dimensions represent the descriptive attributes of the data, while facts represent the numerical measurements or metrics. By utilizing a star schema or snowflake schema, dimensional modeling simplifies complex data structures and enables efficient querying and analysis.
When implementing dimensional modeling, it is important to carefully design the dimensions and facts to ensure accurate and meaningful analysis. The dimensions should capture all relevant attributes of the data, such as time, geography, and product. The facts should accurately represent the measurements or metrics that are of interest to the business, such as sales revenue or customer satisfaction scores.
Furthermore, dimensional modeling allows for the creation of hierarchies within dimensions, enabling drill-down and roll-up capabilities. This means that users can easily navigate through different levels of detail in the data, from high-level summaries to granular details.
Overall, dimensional modeling is a powerful technique that provides a solid foundation for data warehousing and business intelligence projects. It enables organizations to effectively organize and analyze their data, leading to valuable insights and informed decision-making.
Data Vault Modeling: A Flexible and Dynamic Approach
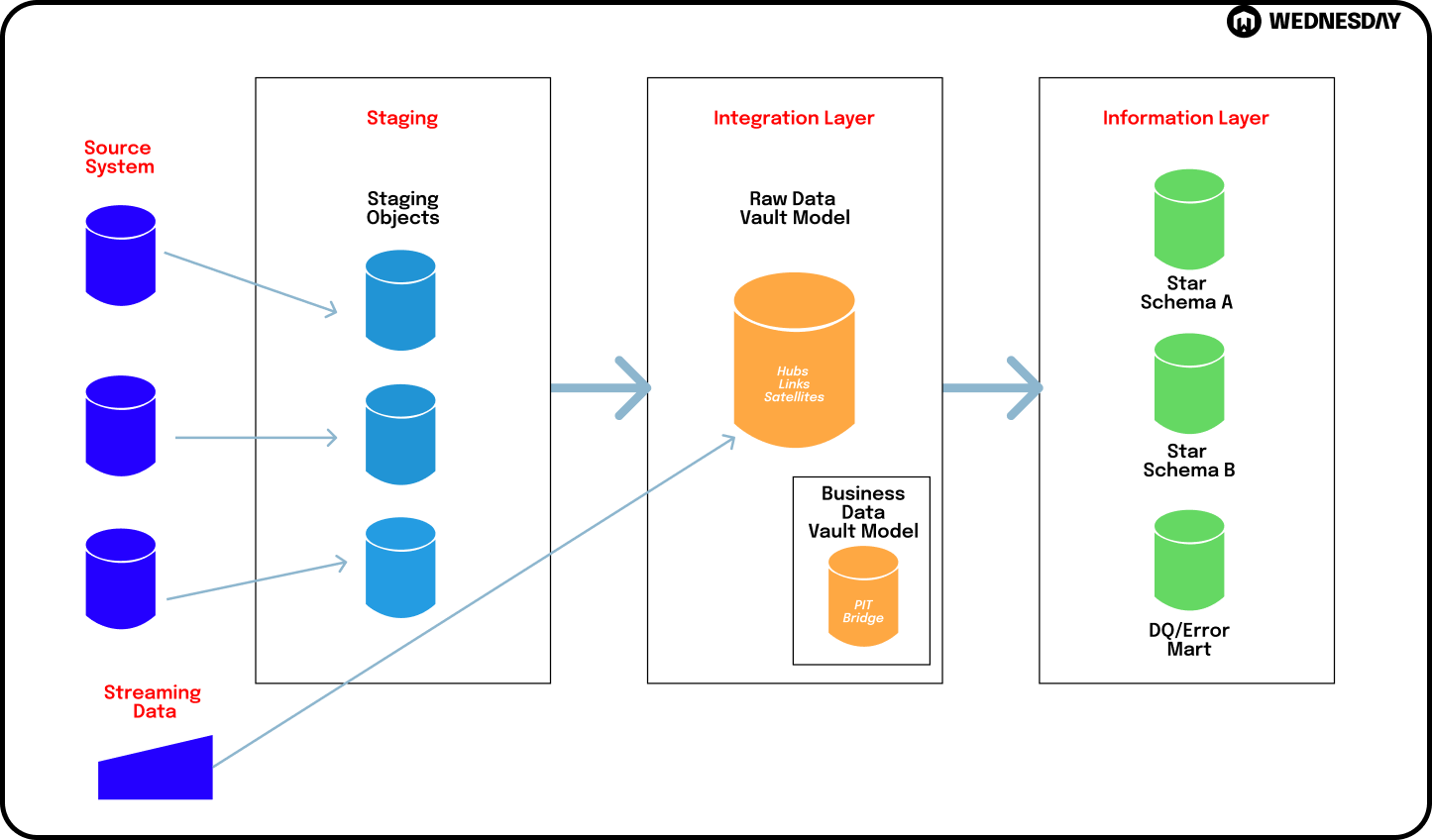
Another powerful technique in data modeling is Data Vault modeling. It focuses on delivering a flexible and scalable solution for data warehousing and data integration projects.
Data Vault modeling utilizes three main types of tables: hub, link, and satellite tables. The hub tables represent the core business entities, the link tables capture the relationships between these entities, and the satellite tables store the additional context or attributes.
This approach offers several benefits, such as easy extensibility, enhanced data traceability, and simplified data integration. It is particularly suitable for dynamic and rapidly evolving business environments.
When implementing Data Vault modeling, it is important to carefully design the hub, link, and satellite tables to ensure optimal performance and scalability. The hub tables should accurately represent the core business entities and their unique identifiers. The link tables should capture the relationships between these entities, allowing for easy navigation and analysis. The satellite tables should store the additional context or attributes, providing a comprehensive view of the data.
Furthermore, Data Vault modeling allows for the separation of historical and current data, enabling efficient data loading and retrieval. This means that organizations can easily track changes over time and analyze historical trends.
Overall, Data Vault modeling is a powerful technique that provides a flexible and scalable solution for data warehousing and data integration projects. It enables organizations to effectively manage and analyze their data, leading to improved decision-making and business outcomes.
Anchor Modeling: Simplifying Complex Data Structures
Complex data structures often pose challenges in data modeling. However, Anchor modeling provides an innovative approach to overcome these challenges.
Anchor modeling focuses on capturing the relationships between data elements, rather than explicitly defining the structure upfront. It utilizes anchors as central reference points and ties together related concepts using predicates and qualifiers. This approach simplifies the modeling process and enables easier adaptability to changing business requirements.
When implementing Anchor modeling, it is important to carefully identify the anchors and their relationships to ensure a comprehensive and accurate representation of the data. The anchors should serve as the central reference points, capturing the core entities or concepts within the domain. The predicates and qualifiers should be carefully defined to accurately represent the relationships between the anchors.
Furthermore, Anchor modeling allows for the easy addition of new data elements or concepts, without the need for extensive restructuring of the data model. This means that organizations can quickly adapt to changing business requirements and incorporate new data sources or attributes.
Overall, Anchor modeling is a powerful technique that simplifies the modeling process and enables easier adaptability to complex data structures. It provides organizations with a flexible and scalable solution for managing and analyzing their data.
Bitemporal Modeling: Handling Historical Data with Ease
Historical data adds another layer of complexity to data modeling. To handle this complexity effectively, bitemporal modeling can be utilized.
Bitemporal modeling allows for the tracking of data changes over time, capturing both validity and transaction time. It enables the storage of multiple versions of data, allowing for powerful analysis and historical trend analysis. This technique plays a critical role in industries where temporal aspects are crucial, such as finance, healthcare, and retail.
When implementing bitemporal modeling, it is important to carefully design the data structures to ensure accurate and efficient storage and retrieval of historical data. The validity time should capture the period during which the data is valid, while the transaction time should capture the period during which the data was recorded or modified.
Furthermore, bitemporal modeling allows for the easy identification of data inconsistencies or anomalies, as it provides a comprehensive view of the data at different points in time. This means that organizations can effectively analyze historical trends and identify patterns or outliers.
Overall, bitemporal modeling is a powerful technique that enables organizations to effectively handle historical data. It provides a comprehensive view of the data at different points in time, allowing for powerful analysis and informed decision-making.
Entity-Centric Data Modeling (ECM): Putting Entities at the Center
Data modeling approaches often revolve around the relationships between entities. However, Entity-Centric Data Modeling (ECM) takes a different perspective by putting entities at the center of the modeling process.
ECM focuses on identifying the core entities within a domain and modeling their attributes and relationships explicitly. This approach simplifies the understanding and maintenance of the data model, leading to improved data quality and productivity.
When implementing ECM, it is important to carefully identify the core entities and their attributes to ensure a comprehensive and accurate representation of the data. The entities should capture the key concepts or objects within the domain, and their attributes should accurately represent the characteristics or properties of these entities.
Furthermore, ECM allows for the easy identification of data dependencies and relationships, as they are explicitly modeled. This means that organizations can easily understand the data model and its underlying structure, leading to improved data quality and productivity.
Overall, ECM is a powerful technique that puts entities at the center of the modeling process. It simplifies the understanding and maintenance of the data model, leading to improved data quality and productivity.
Overcoming Common Challenges in Data Modeling
Addressing Data Redundancy and Inconsistency
Data redundancy and inconsistency can be major roadblocks in data modeling. However, there are effective strategies to tackle these challenges.
Normalization techniques, such as decomposing data into smaller, atomic units, help eliminate redundancy and ensure data consistency. Additionally, implementing proper data validation rules and constraints further enhances data integrity and accuracy.
Ensuring Data Integrity in Data Models
Data integrity is crucial for maintaining high-quality data models. Implementing integrity constraints, such as primary keys, foreign keys, and unique constraints, helps ensure the correctness and consistency of the data.
Regular data quality checks and validation processes are also essential to detect and rectify any inconsistencies or errors in the data. By prioritizing data integrity, organizations can rely on their data models as reliable sources of information.
Handling Data Model Scalability and Performance
As data volumes continue to grow exponentially, scalability and performance become critical considerations in data modeling.
Techniques such as indexing, partitioning, and query optimization can significantly improve the performance of data models. Ensuring the appropriate choice of data types, minimizing data redundancy, and optimizing storage structures are also vital for scalability.
Moreover, distributed and parallel processing techniques, coupled with efficient hardware and software configurations, enable the handling of large-scale data models without compromising performance.
Where to go from here?
In conclusion, mastering data modeling approaches is key to unlocking the power of data engineering. Understanding the different types of data models, exploring various modeling techniques, and addressing common challenges are essential steps towards building effective and efficient data models. By harnessing the power of data modeling, organizations can unleash the true potential of their data and drive informed decision-making.
Ready to elevate your data engineering capabilities and transform your business with expertly crafted data models? Wednesday is here to guide you through every step of the journey. If you’d like to explore our services book a free consult here.
Enjoyed the article? Join the ranks of elite C Execs who are already benefiting from LeadReads. Joins here.
