

Open data management is a critical aspect of modern organizations that rely on data-driven decision-making. To effectively manage open data, organizations need a comprehensive stack of tools that enable seamless data integration, powerful data transformation, efficient data orchestration, and insightful data visualization. In this comprehensive guide, we will explore the core tools of the open data stack, discuss their key features and benefits, and provide valuable insights into their applications and usage.
The Core Tools of the Open Data Stack
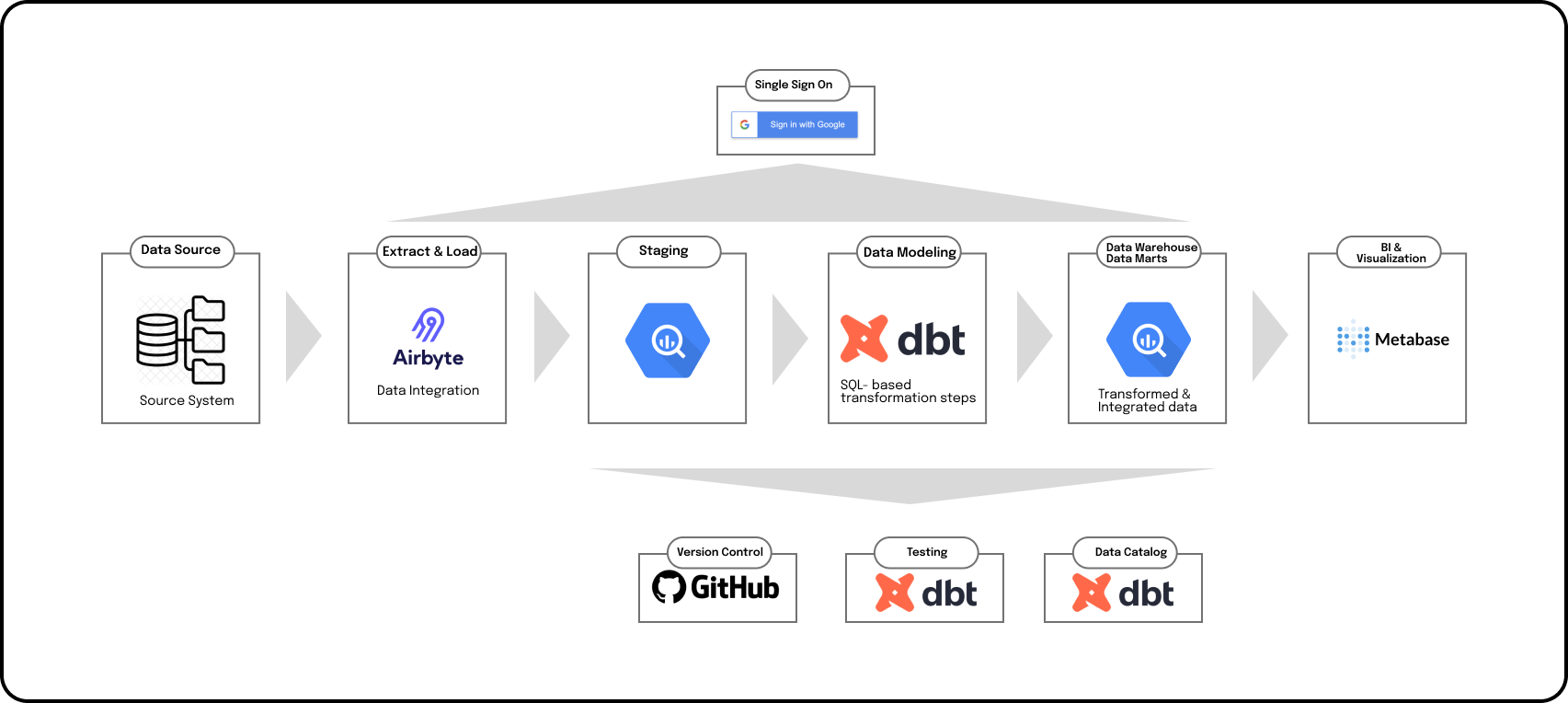
Exploring Airbyte: The Key to Seamless Data Integration
Data integration is often a complex and time-consuming process that involves extracting data from various sources, transforming it into a unified format, and loading it into a data warehouse or data lake. Airbyte simplifies this process by providing a powerful and user-friendly platform for data integration.
With its intuitive interface and support for a wide range of connectors, Airbyte streamlines the process of connecting to different data sources, mapping data fields, and scheduling data synchronization. Whether you need to integrate data from databases, APIs, file systems, or other sources, Airbyte has got you covered.
Imagine you are a data analyst working on a project that requires integrating data from multiple sources. With Airbyte, you can easily connect to your company's CRM system, extract customer data, and combine it with data from your marketing automation platform. This seamless integration allows you to gain a holistic view of your customers and make data-driven decisions to optimize your marketing campaigns.
dbt: Unlocking the Power of Data Transformation
Data transformation is a critical step in the data management process. It involves cleaning, filtering, aggregating, and enriching data to make it more useful for analysis and decision-making. dbt (data build tool) is a popular open-source tool that simplifies data transformation by providing a powerful SQL-based workflow.
With dbt, you can define transformation models, run tests to ensure data quality, and generate documentation to enhance data understanding. Whether you're a data engineer, analyst, or scientist, dbt empowers you to transform data with ease and efficiency.
Let's say you are a data engineer tasked with preparing a dataset for analysis. With dbt, you can easily clean and filter the data, remove duplicates, and aggregate it to the desired granularity. You can also enrich the dataset by joining it with external data sources, such as demographic information or market trends. This comprehensive data transformation process sets the stage for insightful analysis and informed decision-making.
Metabase: Simplifying Analytics and Data Visualization
Analytics and data visualization are essential for extracting insights from data and communicating them effectively. Metabase is an open-source analytics and visualization tool that simplifies the process of exploring data and creating insightful dashboards and reports.
With its intuitive interface and powerful querying capabilities, Metabase allows users to explore data in a visual and interactive way. Whether you're a business user or a data analyst, Metabase empowers you to uncover valuable insights and tell compelling data stories.
Imagine you are a marketing manager analyzing the performance of your latest email campaign. With Metabase, you can easily create a dashboard that visualizes key metrics such as open rates, click-through rates, and conversion rates. You can also segment the data by different customer demographics or campaign variants to identify patterns and optimize your marketing strategy. The ability to visually explore and analyze data in real-time enables you to make data-driven decisions that drive business growth.
Dagster: Streamlining Data Orchestration with Python
Data orchestration is the process of managing and coordinating data pipelines and workflows. It involves scheduling data jobs, handling dependencies, and monitoring data processing. Dagster is a Python-based tool that enables efficient data orchestration by providing a structured and scalable approach to building data pipelines.
With Dagster, you can define data pipelines as executable graphs, manage their execution, and monitor their performance. Whether you're dealing with batch processing or real-time streaming data, Dagster can help you streamline data orchestration and ensure data reliability.
Let's say you are a data engineer responsible for building a data pipeline that processes and analyzes real-time streaming data from IoT devices. With Dagster, you can easily define the different stages of your pipeline, such as data ingestion, transformation, and analysis. You can also set up alerts and monitoring to ensure the pipeline is running smoothly and detect any issues in real-time. This streamlined data orchestration process allows you to focus on extracting valuable insights from the data rather than worrying about the underlying infrastructure.
Getting Started with the Open Data Stack
Why Choose Airbyte for Data Integration?
When it comes to data integration, Airbyte is a standout choice. Its user-friendly interface makes connecting to different data sources a breeze. With just a few clicks, you can effortlessly map data fields and configure synchronization settings. But that's not all - Airbyte also boasts an extensive connector library, ensuring seamless integration with popular databases, file formats, cloud services, and more. And to top it off, Airbyte's robust scheduling capabilities allow you to automate data synchronization, keeping your data always up to date.
Mastering Data Transformation with dbt
Data transformation is a critical step in the data pipeline, and dbt is here to simplify the process. With its SQL-based workflow, dbt maximizes efficiency and maintainability. Transformation models, testing frameworks, and documentation generation are just a few of the powerful features that dbt offers. By adopting dbt, organizations can ensure data quality, enhance data understanding, and foster collaboration between data engineers, analysts, and scientists. With dbt, mastering data transformation becomes an achievable goal.
Unleashing the Potential of Metabase for Analytics and Visualization
Analytics and visualization are key to unlocking the true value of your data, and Metabase is the tool to help you do just that. With its intuitive interface and powerful querying capabilities, Metabase empowers users to explore data and uncover valuable insights. Creating interactive dashboards and reports is a breeze with Metabase, allowing stakeholders to access and visualize data in a meaningful way. By unleashing the potential of Metabase, organizations can democratize data analytics and drive data-driven decision-making at all levels.
Simplifying Data Orchestration with Dagster
Data orchestration can be complex, but Dagster is here to simplify the process. With its structured and scalable approach to building data pipelines, Dagster allows developers to define data pipelines as executable graphs. This Python-based interface makes it easy to understand and maintain data pipelines. And with its powerful execution engine and monitoring capabilities, Dagster ensures that your data pipelines run smoothly and reliably. By simplifying data orchestration, Dagster allows organizations to focus on extracting value from data rather than managing complex workflows.
Expanding Your Open Data Stack

Exploring Additional Components for Enhanced Data Management
While the core tools discussed above cover key aspects of open data management, there are several additional components that can enhance the capabilities of your open data stack. These include tools for data quality management, data cataloging, data governance, and data lineage.
When it comes to data quality management, having the right tools in place is crucial. These tools help you identify and address data anomalies, inconsistencies, and errors, ensuring that your open data is reliable and trustworthy. With robust data quality management tools, you can establish data quality rules, perform data profiling, and monitor data quality metrics to ensure that your data meets the highest standards.
Data cataloging is another important component to consider. A data catalog acts as a centralized repository for all your open data assets, making it easier for users to discover, understand, and access the data they need. By implementing a data catalog, you can create a comprehensive inventory of your open data, including metadata, data lineage, and data usage information. This not only improves data discoverability but also facilitates data governance and compliance.
Data governance is essential for organizations that deal with open data. It involves defining policies, procedures, and standards for data management, ensuring that data is handled in a secure, compliant, and ethical manner. By incorporating data governance tools into your open data stack, you can establish data ownership, define data access controls, and enforce data privacy regulations. This helps maintain data integrity, protect sensitive information, and build trust with data consumers.
Data lineage is another critical component that provides visibility into the origins and transformations of your open data. By tracking the lineage of your data, you can understand how it has been derived, what processes it has gone through, and how it has been transformed over time. This not only helps in troubleshooting data issues but also enables data auditing, compliance, and regulatory reporting.
Where to go from here?
In conclusion, open data management requires a comprehensive stack of tools that enable seamless data integration, powerful data transformation, efficient data orchestration, and insightful data visualization. By leveraging the core tools of the open data stack, such as Airbyte, dbt, Metabase, and Dagster, organizations can unlock the full potential of their data and drive data-driven decision-making. Additionally, by exploring additional components for enhanced data management, organizations can further strengthen their open data stack and ensure data accuracy, consistency, and collaboration. With the right tools in place, organizations can confidently navigate the challenges and opportunities of open data and empower their teams to make informed decisions based on accurate and valuable insights.
As you explore the vast landscape of open data management and the essential tools that can transform your organization's approach to data, remember that an experienced partner can help you in this journey. If you’d like to explore our services and know how we can help please schedule a free consult here.
Enjoyed the article? Join the ranks of elite C Execs who are already benefiting from LeadReads. Joins here.
