

I have watched more startup product launches fail because of brittle infrastructure than because of bad ideas. The pattern is consistent: a founder spends months perfecting their pitch deck, refining their landing page, and building anticipation, only to have the product buckle under its first hundred users. Signup flows break. Database queries time out. Deployments require a prayer and a weekend. By the time the team patches the holes, the launch momentum is gone, and the early adopters have moved on. A startup product launch is not a marketing event. It is an engineering event, and the teams that treat it as such are the ones that survive past month six.
A startup product launch is when you move your product from development to a live system where real users start using it under actual conditions. How well you handle this transition decides if early user interest turns into lasting growth or fades away into lost customers.

Resilient digital infrastructure visualization for a successful startup product launch.
TL;DR: Most startup product launches fail not because of poor market fit but because of engineering decisions made (or avoided) in the weeks before going live. Teams that invest in deployment automation, production-grade monitoring, and a tested rollback strategy before launch day outperform those that treat launch as a marketing milestone. The technical foundation laid during pre-launch determines whether a startup can iterate fast enough to find product-market fit before capital runs out.
Pre-launch engineering is a separate discipline from product development
Most founders I work with assume that once the features are built, the product is ready to launch. That assumption has cost more runway than any failed marketing campaign. Building features and preparing for a launch are two different engineering activities with different goals, different risks, and different failure modes.
When building features, you focus on learning quickly. You want fast feedback loops, throwaway prototypes, and the freedom to pivot. When preparing for launch, you focus on making sure everything works reliably in real situations. You are asking different questions: What happens when 500 users hit the signup endpoint simultaneously? What happens when a third-party API goes down mid-transaction? What happens when you need to roll back a deployment at 2 AM with no senior engineer online?
I have seen teams ship beautiful products that worked perfectly in staging and fell apart in production because nobody load-tested the database layer. I have seen founders lose their first 200 users because a deployment script silently failed and nobody noticed for 12 hours. According to Technotrenz product launch statistics, nearly 95 percent of new products fail to meet their launch targets, and a significant share of those failures trace back to technical readiness, not market demand.
The right approach is to treat pre-launch as its own phase with its own checklist, its own timeline, and its own budget. It starts when feature development is frozen, not when the marketing team schedules the Product Hunt post.
Architecture decisions that survive contact with real users
The architecture you ship with does not need to scale to a million users. It needs to survive the first thousand without breaking, and it needs to be modifiable fast enough to respond to what those users tell you. I have seen founders over-engineer their stack for hypothetical scale while under-engineering it for the iteration speed they actually need.
The right architecture for a startup product launch is one that prioritizes three properties: deployability, observability, and modifiability. Deployability means you can ship changes multiple times per day without downtime. Observability means you can see what is happening in production without SSH-ing into a server. Modifiability means you can change one part of the system without breaking three others.
Monolith versus microservices is the wrong debate at this stage. I have launched products on a well-structured monolith that shipped three times a day and products on microservices that took a week to deploy because the team was debugging inter-service authentication. The question is not monolith or microservices. The question is: can you deploy a change, see its impact, and roll it back within an hour? If the answer is yes, the architecture is fine. If the answer is no, no amount of trendy infrastructure will save you.
One pattern I push hard on is separating your deployment pipeline from your feature code. Your CI/CD pipeline is infrastructure, not a feature. It should be set up before the first user-facing feature is built, not bolted on after the product is "done." The teams that do this consistently ship faster and break less during launch week.
This is where the sprint-based approach we use in Launch engagements makes a measurable difference: by structuring development into outcome-driven sprints, each sprint produces a deployable increment that has already been tested against production-like conditions, so launch day is not a leap of faith.
The deployment pipeline is your most important product
I learned this the hard way. Early in my career, I spent three weeks building a feature and thirty minutes setting up the deployment pipeline. On launch day, the pipeline failed silently, the feature deployed to the wrong environment, and we lost six hours of launch traffic while the team scrambled to fix it. Since then, I treat the deployment pipeline as a product with its own requirements, its own tests, and its own quality bar.
A launch-ready deployment pipeline does five things: it builds the application from source, runs the full test suite, deploys to a staging environment that mirrors production, runs smoke tests against the staging deployment, and promotes to production with a single command or click. If any step fails, the pipeline stops and alerts the team. No step should require manual intervention or tribal knowledge.
Rollback is not optional. It is the most important feature of your deployment pipeline. I require every launch-ready pipeline to support a one-command rollback to the previous version. This is not about pessimism. It is about giving the team confidence to deploy frequently, which is the single strongest predictor of launch success. Teams that can roll back quickly deploy more often, which means they ship fixes faster, which means they recover from launch-day issues in minutes instead of days.
Feature flags are the second most important pipeline feature. They let you ship code to production without exposing it to users. This means you can merge and deploy features incrementally during the weeks before launch, reducing the blast radius of any single change. On launch day, you flip the flags. No risky big-bang deployments. No all-night deployment marathons.
Most teams treat launch as a marketing milestone with a technical component. The teams that survive treat launch as a technical milestone with a marketing component. The difference is not semantic, it is structural: it determines whether engineering has a veto on launch timing.
Testing strategy for launch confidence, not coverage metrics
Code coverage is a vanity metric that makes engineers feel productive without guaranteeing anything about production behavior. I have seen test suites with 90 percent coverage that failed to catch the exact bug that crashed the product on launch day, because the tests were testing the wrong things.
The testing strategy I recommend for a startup product launch is built around failure modes, not code paths. Start by listing every way the product can fail in front of a real user. Signup flow breaks. Payment processing times out. Email verification never arrives. Data gets corrupted during concurrent writes. Then write tests that verify each failure mode is handled gracefully. These are not unit tests. They are integration and end-to-end tests that simulate real user behavior.
Load testing is the most skipped and most important pre-launch activity. You do not need to simulate a million concurrent users. You need to simulate ten times your expected launch-day traffic and see where the system breaks. In my experience, the bottleneck is almost never the application code. It is the database, the third-party API rate limits, or the CDN configuration. Finding these bottlenecks before launch, when you have time to fix them, is worth more than any feature you could build in the same time window.
Security testing matters more than most early-stage teams realize. A data breach in your first month can be fatal, not just legally but reputationally. At minimum, run a dependency vulnerability scan, test your authentication flows for common exploits, and verify that your API endpoints reject malformed input. These are not enterprise-grade security audits. They are basic hygiene that prevents catastrophic launch-day incidents.
Monitoring and observability from day one of production
The first hour after launch tells you more about your product than the previous three months of development. But only if you can see what is happening. I have watched founders launch a product with zero monitoring, celebrate on Twitter for two hours, and then discover that 40 percent of signups were failing silently because of a database connection pool exhaustion. By the time they found out, those users were gone.
Production monitoring for a startup product launch does not require a dedicated observability platform or a team of SREs. It requires three things: error tracking that captures and alerts on unhandled exceptions, performance monitoring that tracks response times for your critical endpoints, and uptime monitoring that pings your health check endpoint every minute. All three can be set up in a day with modern tools.
The critical endpoints are the ones that represent user value. For most products, that is the signup flow, the core action (whatever the product does), and the billing flow. If any of these endpoints degrade, you need to know within minutes, not hours. Set up alerts that fire when error rates exceed a threshold or response times spike. Do not set up alerts for everything. Alert fatigue is real, and an engineer who ignores alerts is worse than no alerts at all.
Structured logging is the observability investment that pays the most dividends during launch week. When a user reports a bug, you need to trace their exact path through the system. This requires correlation IDs, request-scoped logging, and log levels that let you filter noise from signal. I have debugged launch-day issues in minutes with good logging and in hours without it. The difference compounds over a week of launch.
The launch day playbook nobody writes down
Every team has a launch day plan. Almost none of them write it down. The ones that do write it down almost never rehearse it. I have seen launch day plans that looked great in a Notion doc and fell apart because nobody had actually practiced the rollback procedure or verified that the on-call engineer had the right access permissions.
A launch day playbook is a runbook that covers the first 72 hours of production. It includes the exact deployment steps with timestamps, the rollback procedure with a decision tree (if X happens, roll back; if Y happens, investigate), the on-call rotation with phone numbers, the escalation path for different severity levels, and a communication plan for internal and external stakeholders. It should be written by the engineer who will execute it, reviewed by the team lead, and dry-run at least once before launch.
The most overlooked section is the go, no-go checklist. This is a pre-launch gate that the team reviews together before flipping the switch. It covers: all critical tests passing, monitoring and alerts verified, rollback tested, on-call engineer confirmed and available, third-party dependencies checked, and a clear definition of what constitutes a launch-blocking issue versus a post-launch fix. I have seen teams skip this checklist because they were confident, and I have seen those same teams spend launch day firefighting instead of celebrating.
Post-launch triage is equally important. Not every bug needs to be fixed immediately. The playbook should include a triage framework: what gets fixed within the hour, what gets fixed within the day, what gets added to the backlog. Without this framework, the team chases every user report and ends up fixing cosmetic issues while a critical data integrity bug sits unaddressed.
Why most startup product launches fail technically, and how to avoid it
Across the launches I have been involved with, the technical failures fall into three categories, and they are all preventable. The first is the big-bang deployment: everything ships at once, something breaks, and the team cannot isolate the issue because ten things changed simultaneously. The second is the missing rollback: the team deploys, discovers a critical bug, and has no way to revert to the previous version without a manual database migration. The third is the silent failure: something breaks, but there is no monitoring to detect it, so the team discovers the problem through user complaints hours later.
The antidote to all three is discipline, not tooling. Incremental deployments with feature flags prevent big-bang failures. Tested rollback procedures prevent the missing rollback scenario. Basic monitoring and alerting prevent silent failures. None of these require expensive tools or large teams. They require the discipline to set them up before launch, test them before launch, and trust them during launch.
MaRS Discovery District found that successful launches prioritize a lean product version with clear goals and pre-launch audience engagement. I would add that the lean product version must be deployed on infrastructure that can be modified, monitored, and rolled back without heroics. A lean product on fragile infrastructure is not lean. It is fragile.
The founders who get this right are the ones who allocate the last two to four weeks before launch exclusively to pre-launch engineering. No new features. No design tweaks. No scope additions. Just hardening, testing, and rehearsal. It feels slow in the moment. It feels fast when launch day goes smoothly.
Conventional advice says to launch fast and fix later. In practice, the startups that find product-market fit are the ones that launch a stable product and iterate fast. Stability on day one earns you the credibility and user trust that makes iteration possible. A buggy launch does not give you data, it gives you churn.
How a Series A logistics startup turned a chaotic launch plan into a controlled release
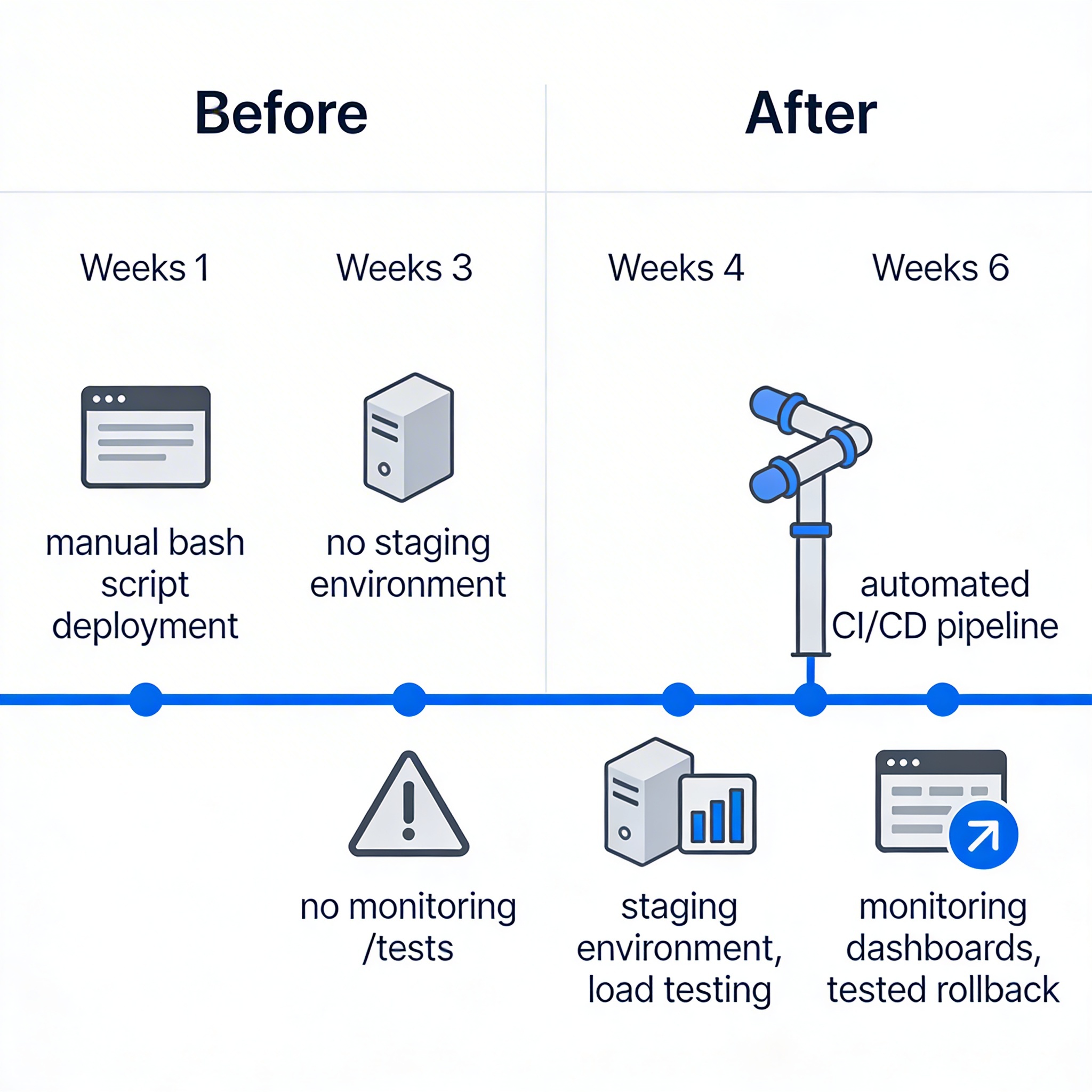
A logistics startup came to us six weeks before their planned launch. They had built a fleet management platform for mid-size delivery companies. The product was feature-complete, but the deployment process was a bash script that one engineer ran manually from their laptop. There was no staging environment. No automated tests beyond a handful of unit tests. No monitoring. The founder told me, with some pride, that they were going to launch fast and iterate.
I told them they were going to launch broken and churn users. We spent the first two weeks building a proper CI/CD pipeline with automated builds, test execution, and deployment to a staging environment that mirrored production. We added integration tests for the three critical flows: driver onboarding, route assignment, and delivery confirmation. We set up error tracking with Sentry, performance monitoring on the core API endpoints, and uptime checks on the health endpoint.
Weeks three and four were dedicated to load testing and hardening. We simulated 500 concurrent drivers hitting the route assignment endpoint and found that the database connection pool was configured for 20 connections. That single misconfiguration would have caused cascading timeouts on launch day. We also found that the third-party mapping API had a rate limit that would have been hit within the first hour of real traffic. We implemented caching and request batching, which reduced API calls by 70 percent.
Week five was rehearsal. We ran a full deployment to staging, verified all monitoring and alerts, tested the rollback procedure twice, and wrote a launch day playbook with a go, no-go checklist. The on-call engineer practiced the rollback until it took under four minutes.
Launch day was uneventful, which is the highest compliment a launch can receive. The product handled 340 concurrent users in the first hour. Error rates stayed below 0.5 percent. Two minor bugs were caught by monitoring before any user reported them, and both were fixed within 30 minutes using the feature flag system. The founder told me afterward that the launch felt boring. I told him that boring is the goal.
If you are two to four weeks from a startup product launch and you do not have a tested deployment pipeline, production monitoring, and a written rollback procedure, your launch is at risk. The fix is not to delay the launch. The fix is to stop building features and start building launch infrastructure. Every day you spend on features instead of launch readiness increases the probability that launch day becomes a firefight instead of a milestone.
The teams that ship reliably are the ones that treat pre-launch engineering as non-negotiable. If you want to understand what this looks like in practice, the way we structure outcome-driven sprints in our Launch engagements is designed to produce deployable, tested increments at every stage, so that launch day is a controlled release, not a leap of faith.
FAQs
What's the biggest technical mistake founders make before a startup product launch?
Treating launch as a marketing event, not an engineering one. The blog shows most failures come from brittle infrastructure, not bad ideas.
How can I get free cloud credits for my startup launch?
Major vendors like AWS, Google Cloud, and Microsoft offer startup programs with credits. These are key launch enablers competitors often mention.
What role do launch platforms like Product Hunt play?
They're part of the GTM strategy, but only after engineering readiness. The blog warns against scheduling posts before infrastructure is production-grade.
Last updated: March 18, 2026
